
今後の数学的な分析のために必要な基礎知識として、知りたかったことをGeminiに教わったので、同じ質問をしなくて済むように残しておく。
0~1内の数字xを一つ選び、ランダムに(n-1)個選んで、n個の中から大きい順にm個選びます。xがm個の中に選ばれる確率f(x)と、xが選ばれている状態で別の数字yがm個の中に選ばれる確率f(y|x+)と、xが選ばれていない状態で別の数字yがm個の中に選ばれる確率g(y|x-)の数式を教えてください。
指定された条件($n$個の数字の中から大きい順に$m$個を選ぶ)において、ある数字が選ばれる(=上位$m$個に入る)ということは、「他の数字のうち、その数字よりも大きいものが$m-1$個以下である」と言い換えることができます。
数字は$0$から$1$の範囲でランダムに選ばれるため、ある基準値$v$に対して他の1つの数字が$v$より大きくなる確率は$1-v$、小さくなる確率は$v$となります。これをもとに二項分布の累積確率を用いて計算した数式を以下に示します。
なお、$y$は$x$とは異なる別の数字($y \neq x$)であることを前提とし、$x$と$y$の大小関係によって条件付き確率の論理構造が変わるため、場合分けを行っています。
1. $x$が$m$個の中に選ばれる確率 $f(x)$
自身以外の$n-1$個の数字のうち、$x$より大きい数字が$m-1$個以下となる確率です。
$$f(x) = \sum_{k=0}^{m-1} \binom{n-1}{k} (1-x)^k x^{n-1-k}$$
2. $x$が選ばれている状態で、別の数字$y$が選ばれる確率 $f(y|x+)$
$x$が選ばれるという条件のもとで、$y$も選ばれる確率です。
$y > x$ の場合、$x$が上位$m$個に入っているならば、それより大きい$y$は論理的に必ず上位$m$個に入ります。逆に $y < x$ の場合は、$x$が自身より大きい$y$の枠を1つ消費するため、残りの$n-2$個の数字の分布から確率を求めます。
$$f(y|x+) = \begin{cases} 1 & (y > x) \\ \frac{ \sum_{k=0}^{m-2} \binom{n-2}{k} (1-y)^k y^{n-2-k} }{ \sum_{k=0}^{m-1} \binom{n-2}{k} (1-x)^k x^{n-2-k} } & (y < x) \end{cases}$$
3. $x$が選ばれていない状態で、別の数字$y$が選ばれる確率 $g(y|x-)$
$x$が選ばれなかった(=上位$m$個に入れなかった)という条件のもとで、$y$が選ばれる確率です。
$y < x$ の場合、$x$が上位$m$個から漏れたのであれば、それより小さい$y$は論理的に絶対に選ばれません。$y > x$ の場合は、$y$が選ばれる事象から「$y$と$x$が共に選ばれる事象」を除外することで導出します。
$$g(y|x-) = \begin{cases} \frac{ \sum_{k=0}^{m-1} \binom{n-2}{k} (1-y)^k y^{n-2-k} - \sum_{k=0}^{m-2} \binom{n-2}{k} (1-x)^k x^{n-2-k} }{ 1 - \sum_{k=0}^{m-2} \binom{n-2}{k} (1-x)^k x^{n-2-k} } & (y > x) \\ 0 & (y < x) \end{cases}$$
【数式の計算上の注意点】
- $\binom{n}{k}$ は二項係数(組み合わせ) $\frac{n!}{k!(n-k)!}$ を表します。
- $m=1$ の場合など、$\sum$記号の上限値が下限値($0$)より小さくなる項(例:$\sum_{k=0}^{-1}$)が発生した場合は、その和は計算上 $0$ として扱います。
各項の解説は次の通り。
各式の$\sum$の範囲(上限値)は、「残り$n-2$個のランダムな数字のうち、対象の数字($x$または$y$)を上回ることが許容される最大数」を直接的に表しています。上位$m$個に入るための基本条件は「自分より大きい数字が$m-1$個以下」です。
$x$と$y$の大小関係が事前に確定しているため、相手が上位枠($m-1$個)の枠を1つ消費するか否かで$\sum$の許容範囲が$m-1$から$m-2$へとシフトします。以下に最終的な項の構造を示します。
$f(y|x+)$ の項解説($y < x$ の場合)
分子:$\sum_{k=0}^{m-2} \binom{n-2}{k} (1-y)^k y^{n-2-k}$
- 意味: $y < x$ の条件下で、$y$が上位$m$個に入る確率。
- $\sum$の範囲($0$から$m-2$): $x$が確実に$y$より大きい数字として「1枠」を消費しています。$y$が上位$m$個に入るには、残り$n-2$個の数字の中で$y$を上回るものが最大でも $m-1 - 1 = m-2$ 個以下でなければなりません。
分母:$\sum_{k=0}^{m-1} \binom{n-2}{k} (1-x)^k x^{n-2-k}$
- 意味: $y < x$ という前提のもとで、$x$が上位$m$個に入る確率。
- $\sum$の範囲($0$から$m-1$): $y$は$x$より小さいため、$x$より大きい数字の枠を一切消費しません。したがって、残り$n-2$個の中で$x$を上回る数字は基本条件通り最大 $m-1$ 個まで許容されます。
$g(y|x-)$ の項解説($y > x$ の場合)
分子:$\sum_{k=0}^{m-1} \binom{n-2}{k} (1-y)^k y^{n-2-k} - \sum_{k=0}^{m-2} \binom{n-2}{k} (1-x)^k x^{n-2-k}$
- 意味: 「$y$が選ばれる確率」から「$y$と$x$が両方選ばれる確率」を除外した事象の確率。
- 第1項の$\sum$の範囲($0$から$m-1$): $y$が上位$m$に入る確率です。$x$は$y$より小さく枠を消費しないため、残り$n-2$個中、$y$を上回る数字は最大 $m-1$ 個まで許容されます。
- 第2項の$\sum$の範囲($0$から$m-2$): $x$も同時に上位$m$に入る確率です。$y > x$ により$y$が上位枠を1つ消費しているため、$x$が生き残るには残り$n-2$個中、$x$を上回る数字が最大 $m-2$ 個以下である必要があります。
分母:$1 - \sum_{k=0}^{m-2} \binom{n-2}{k} (1-x)^k x^{n-2-k}$
- 意味: $y > x$ という前提のもとで、$x$が上位$m$個から「漏れる」確率。
- $\sum$の範囲($0$から$m-2$): 右辺の$\sum$部分は「$x$が選ばれる確率」です。ここでも$y > x$ により$y$が1枠を消費しているため、$x$が選ばれるための上限は $m-2$ となります。これを全体($1$)から引くことで、選ばれない確率を導出しています。
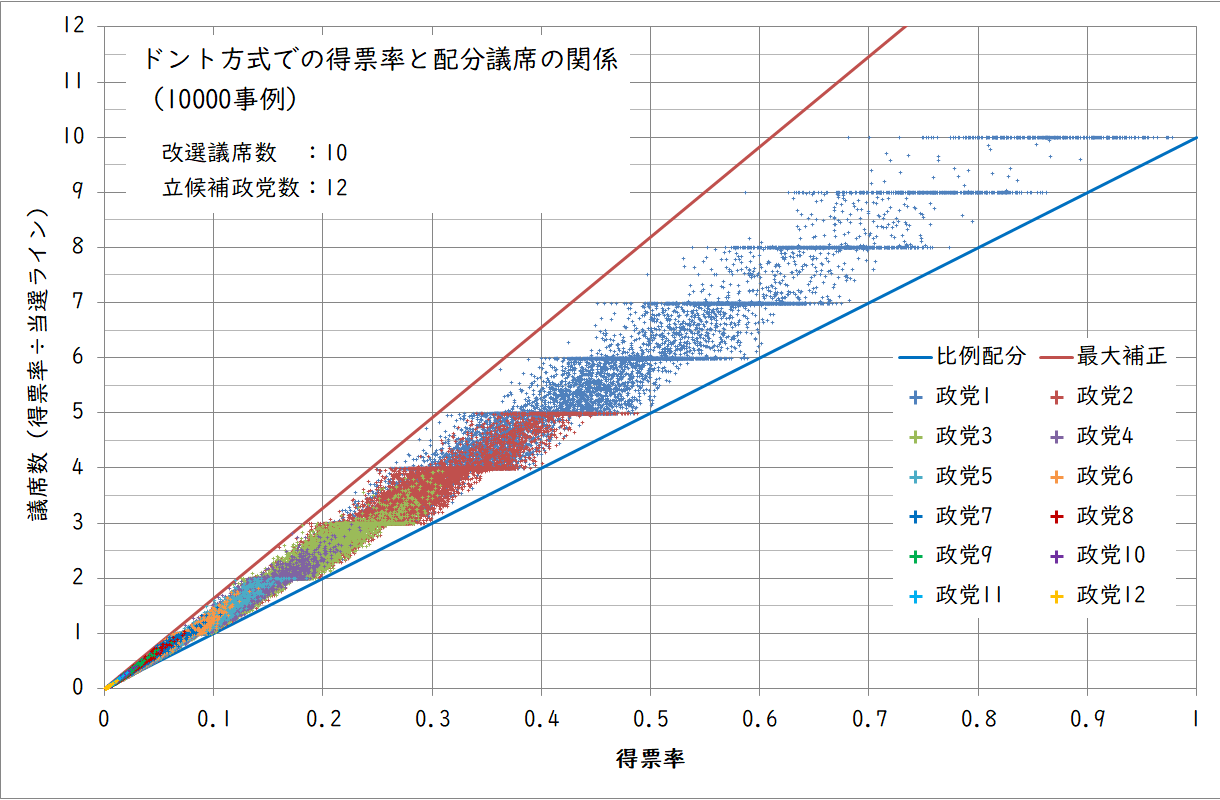
コメント
#Excel を使ってシミュレーションする際のヒントを #Copilot に教わった。
--
結論から言うと、**Excel 2007 には、この P を“そのまま一発で計算する関数”は存在しません**。
しかし **BINOMDIST(累積)を使えば完全に同じ値を求められます**。
---
## 結論:この式は「二項分布の累積分布(CDF)」そのもの
あなたの式
\[
P=\sum_{k=0}^{R-1}\binom{m-1}{k}(1-q)^k q^{m-1-k}
\]
は、次の二項分布の累積確率です:
- **試行回数**:\(n = m-1\)
- **成功確率**:\(p = 1-q\)
- **成功回数が \(R-1\) 以下になる確率**
つまり:
\[
P = \Pr(X \le R-1),\quad X\sim\mathrm{Binomial}(m-1,\,1-q)
\]
---
## ✔ Excel 2007 での対応関数
Excel 2007 には **BINOMDIST** があり、累積を TRUE にすると CDF になります。
### **Excel 2007 の式**
```
=BINOMDIST(R-1, m-1, 1-q, TRUE)
```
これがあなたの P と完全に一致します。
---
## なぜ一致するのか(簡潔に)
- 二項分布の定義
\[
\Pr(X=k)=\binom{n}{k}p^k(1-p)^{n-k}
\]
- あなたの式は
- \(n = m-1\)
- \(p = 1-q\)
- 和の範囲は \(k=0\) から \(R-1\)
- よって
\[
\sum_{k=0}^{R-1}\binom{m-1}{k}(1-q)^k q^{m-1-k}
= \Pr(X\le R-1)
\]
---
## 注意点(Excel 2007 特有)
- Excel 2010 以降の **BINOM.DIST** と違い、Excel 2007 は **BINOMDIST** です。
- 引数の順序は
```
BINOMDIST(成功回数, 試行回数, 成功確率, 累積かどうか)
```
---
## 次のステップ(必要なら)
- R, m, q をセル参照にした式を作る
- 逆関数(R を求める)を作る
- 正規近似で高速化する
- Excel 2007 での安定計算方法を検討する
どれを進めますか?
逆関数を求めたい /
セル参照で式を作りたい /
正規近似を使いたい